
본 포스팅은 인프런 데브원영님의 [아파치 카프카 애플리케이션 프로그래밍]의 강의를 수강 후 정리하는 글입니다.
[아파치 카프카 애플리케이션 프로그래밍] 개념부터 컨슈머, 프로듀서, 커넥트, 스트림즈까지!
데브원영 DVWY | 실전 환경에서 사용하는 아파치 카프카 애플리케이션 프로그래밍 지식들을 모았습니다! 데이터 파이프라인을 구축하는데 핵심이 되는 아파치 카프카의 각종 기능들을 살펴보고
www.inflearn.com
1. 아파치 카프카의 탄생과 기본 구조
1-1. 아파치 카프카의 탄생 배경
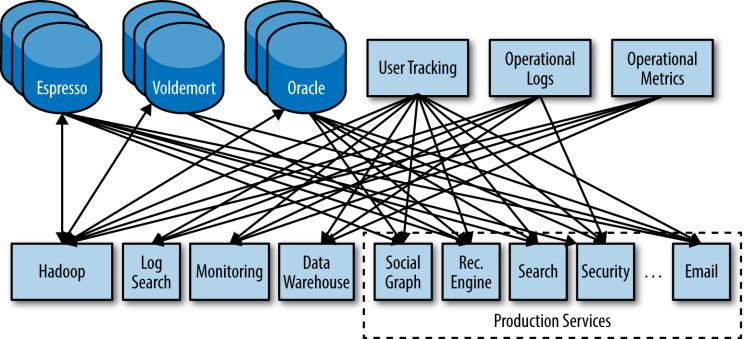
배경: 링크드인에서 분배 아키텍처를 운영하는 데에 큰 어려움
아키텍처가 거대해지고, 소스 애플리케이션과 타깃 애플리케이션 개수가 점점 많아짐
→ 한 곳에 모아 처리할 수 있도록 중앙집중화

1-2. 메시지 큐 구조의 카프카

소스 애플리케이션(프로듀서) → 카프카 → 타깃 애플리케이션(컨슈머)
- 데이터 저장되는 파티션의 동작은 FIFO의 큐 자료구조와 유사함
- 큐와 비슷하지만 컨슈머가 파티션에 있는 데이터를 가져가더라도 파티션에서 삭제되지 않는다.
- 프로듀서가 보낸 데이터는 특정 메시지에 대해서 데이터를 하나 보내게 되면 파티션 중 하나에만 저장
커밋: 특정 컨슈머가 어떤 데이터를 가져갔는지는 내부적으로 기록
2. 빅데이터 파이프라인에 적합한 카프카의 특징
2-1. 높은 처리량
- 많은 양의 데이터를 묶음 단위로 처리하는 배치로 빠르게 처리할 수 있음
- 파티션 개수만큼 컨슈머 개수를 늘린다면 동일 시간당 데이터 처리량이 선형적으로 증가
2-2. 확장성
하루에 1,000건 가량 들어오는 로그 데이터가 예상치 못하게 100만 건 이상 들어와도 안전적으로 확장 가능하도록 설계되었음.
- 데이터가 적을 때: 카프카 클러스터의 브로커를 최소한의 개수로 운영
- 데이터가 많아지면: 카프카 클러스터의 브로커 개수를 늘려서 스케일 아웃(Scale-out)
- 데이터가 적어지면: 카프카 클러스터의 브로커 개수를 줄여서 스케일 인(Scale-in)
⇒ 클러스터의 무중단 운영을 지원하여 365일 34시간 데이터를 처리해야 하는 은행 같은 비즈니스 모델에서도 안정적인 운영 가능
2-3. 영속성
영속성: 데이터를 생성한 프로그램이 종료되더라도 사라지지 않은 데이터의 특성
- 카프카는 다른 메시징 플랫폼과 다르게 전송받은 데이터를 메모리에 저장하지 않고 파일 시스템에 저장
- 보편적으로는 파일 시스템에 저장하는 것은 느리지만, 운영체제 레벨에서 파일 시스템을 최대한 활용
- 파일 I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성
- 한 번 읽은 파일 내용은 메모리에 저장시켰다가 다시 사용하는 방식이라 처리량이 높음
2-4. 고가용성
- 카프카는 클러스터로 이루어져 데이터의 복제가 브로커 간 가능함
- 한 브로커에 장애가 발생하더라도 복제가 된 데이터가 나머지 브로커에 존재하여 지속적으로 데이터 처리 가능
3. 빅데이터 아키텍처의 종류와 카프카의 미래
3-1. 데이터 레이크 아키텍처
원천 데이터로부터 파생된 데이터의 히스토리를 파악하기가 어려웠고, 계속되는 데이터의 가공으로 데이터가 파편화되어 데이터 거버넌스(Data Governance)가 지켜지기 어려웠음
3-2. 람다 아키텍처
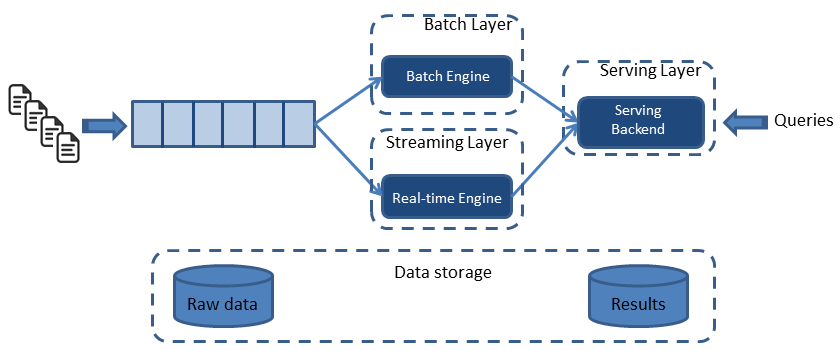
- 배치 레이어: 배치 데이터를 모아서 특정 시간마다 일괄 처리
- 서빙 레이어: 가공된 데이터를 사용자 또는 서비스 애플리케이션이 사용할 수 있도록 저장된 공간
- 스피드 레이어: 원천 데이터를 실시간으로 분석하는 용도
스피드 레이어에 카프카가 위치함
람다 아키텍처의 한계
배치 레이어와 스피드 레이어가 데이터를 분석, 처리하는 데 각각의 레이어에 따로 존재
배치 데이터와 실시간 데이터를 융합하여 처리할 때는 파이프라인이 유연하지 못함
트위터에서 만든 서밍버드로 로직을 추상화하였지만 완전히 해결되지는 않았음
3-3. 카파 아키텍처

Jay Kreps(카프카를 최초로 고안한 개발자)가 카파 아키텍처를 제안
- 배치 레이어를 제거하여 스피드 레이어에서 데이터를 모두 처리
- 카프카가 로그의 배치 데이터와 스트림 데이터를 모두 모아서 활용
- 변환 기록 로그에는 반드시 타임스탬프가 존재해야함
배치 데이터와 스트림 데이터

3-4. 스트리밍 데이터 레이크(카프카의 미래)
- 카파 아키텍처에서 서빙 레이어를 제거함
- 스피드 레이어로 사용되는 카프카에 분석과 프로세싱을 완료한 거대한 데이터를 오랜 기간 동안 저장할 수 있다면, 서빙 레이어는 제거되어도 됨
- 잘 사용하지 않는 데이터를 브로커 내부가 아닌 외부의 오브젝트 스토리지에 저장하면, 브로커의 메모리와 디스크 사용률을 줄일 수 있음
'Kafka' 카테고리의 다른 글
| [Apache Kafka] 3. 카프카 클러스터 운영 (0) | 2024.10.09 |
|---|---|
| [Apache Kafka] 2. 카프카 기본 개념 설명(2) (3) | 2024.10.08 |
| [Apache Kafka] 2. 카프카 기본 개념 설명(1) (1) | 2024.10.01 |
| Kafka - PostgreSQL to MariaDB (2) (0) | 2024.06.30 |
| Kafka - PostgreSQL to MariaDB (1) (1) | 2024.06.30 |